What Are GitLab Environment Variables?
GitLab environment variables are key-value pairs accessible during the execution of CI/CD pipelines in the Gitlab platform. They allow developers to inject dynamic data into job scripts, managing configurations for different environments like development, testing, and production. Instead of hardcoding values, development teams can utilize these variables to improve flexibility and maintainability.
Environment variables can be global, accessible across an entire project, or specific to a pipeline, making them adaptable to various workflows. These variables support automation by offering a way to manage context-specific data efficiently. Whether deploying to multiple environments or handling sensitive information, using environment variables ensures repeatability and improved security.
In this article:
Benefits of Using Environment Variables
Using GitLab environment variables in CI/CD workflows offers several advantages:
- Flexibility: They enable dynamic configuration by allowing users to modify values without changing the code. This is useful when managing multiple environments, like development, staging, and production.
- Simplified maintenance: With environment variables, teams can centralize configuration management. This makes it easier to update values in one place rather than tracking down hardcoded values throughout different scripts.
- Reusability: Variables can be defined globally or locally, enabling developers to reuse the same configurations across different jobs or pipelines without duplication.
- Automation support: By injecting context-specific data into pipelines, environment variables enable automation for deployments, testing, and other CI/CD tasks.
- Consistent deployments: Using predefined variables ensures consistency between pipeline runs, reducing the chances of errors caused by manual inputs.
- Improved security: Environment variables allow teams to store sensitive data, such as API keys and passwords, more securely than if they were hardcoded. However, it should be noted that environment variables are stored in plaintext by default and can still be compromised by attackers. This makes it important to use additional security measures like encryption.
Related content: Read our guide to testing environments
Types of GitLab Environment Variables
Environment variables in GitLab can be predefined or customized.
Predefined Variables
GitLab provides a variety of predefined environment variables to simplify CI/CD operations. These variables automatically populate with data pertinent to the pipeline, job, or system, offering insights such as job details and system paths.
For example, variables like CI_COMMIT_SHA and CI_JOB_NAME provide commit hash and job name information, which can be critical for debugging and deployment tasks. By using these, developers can easily access job and pipeline metadata without custom setups.
Predefined variables also assist in dynamic pipeline configurations. They allow conditions in scripts based on the environment context, facilitating more responsive pipeline behavior. This enables developers to write more adaptable and intelligent scripts that can react to different execution contexts, automatically adjusting operations according to parameters embedded within these predefined environments.
Custom CI/CD Variables
Custom CI/CD variables are user-defined key-value pairs tailored to project needs. They allow developers to add data or behavioral parameters that are absent in predefined variables. Custom variables provide flexibility by enabling project-specific configurations, such as deploying to different regions or selecting feature flags. This helps developers adapt pipeline behavior to meet custom deployment requirements across various environments.
Defining custom variables is straightforward, and they can be set at the project, group, or instance level. They offer control over security by setting sensitive information, like passwords or API keys, without embedding them in the code. This approach secures critical information and supports industry-standard security, separating configuration data from code.
Tips From the Expert
In my experience, here are tips that can help you better utilize GitLab environment variables:
- Use dynamic variable scoping for multi-environment pipelines: Set environment-specific variables dynamically based on the pipeline environment. Use a naming convention like VAR_${CI_ENVIRONMENT_NAME} to minimize hardcoding.
- Combine GitLab variables with external secret managers for layered security
Store sensitive data in tools like HashiCorp Vault or AWS Secrets Manager. Use GitLab’s: integration capabilities to fetch secrets dynamically, reducing dependency on in-repo or UI-stored variables. - Leverage custom scripts to validate variables during pipeline execution: Add a pre-flight script to verify all required variables are defined and correctly scoped before critical stages like deployment. This prevents runtime failures caused by missing or misconfigured variables.
- Use variable precedence to enforce strict overrides: Document and design variable hierarchies to ensure expected values take precedence. For instance, let job-specific variables override group-level variables in critical pipelines.
- Employ JSON or YAML parsing for complex variables: Store complex configurations (e.g., JSON strings) in variables. Use parsing tools in scripts to extract and apply specific values dynamically during execution.

Tutorial: Working with GitLab Environment Variables
This tutorial walks through the process of defining CI/CD variables in a .yml file or through the user interface, configuring security settings, and using variables in job scripts or within other variables.
Define a CI/CD Variable in the .gitlab-ci.yml File
CI/CD variables can be defined directly in the .gitlab-ci.yml file under the variables keyword. This method is best suited for storing non-sensitive data, such as configuration settings or default parameters. Variables defined in this file are visible to anyone with access to the repository, so they should never include sensitive data like passwords or API tokens.
Code example:
variables:
GLOBAL_URL: "https://example.com" # A global variable available to all jobs
build-job:
stage: build
variables:
LOCAL_URL: "https://build.example.com" # A variable specific to this job
script:
- echo "Global URL:$GLOBAL_URL"
- echo "Local URL:$LOCAL_URL"
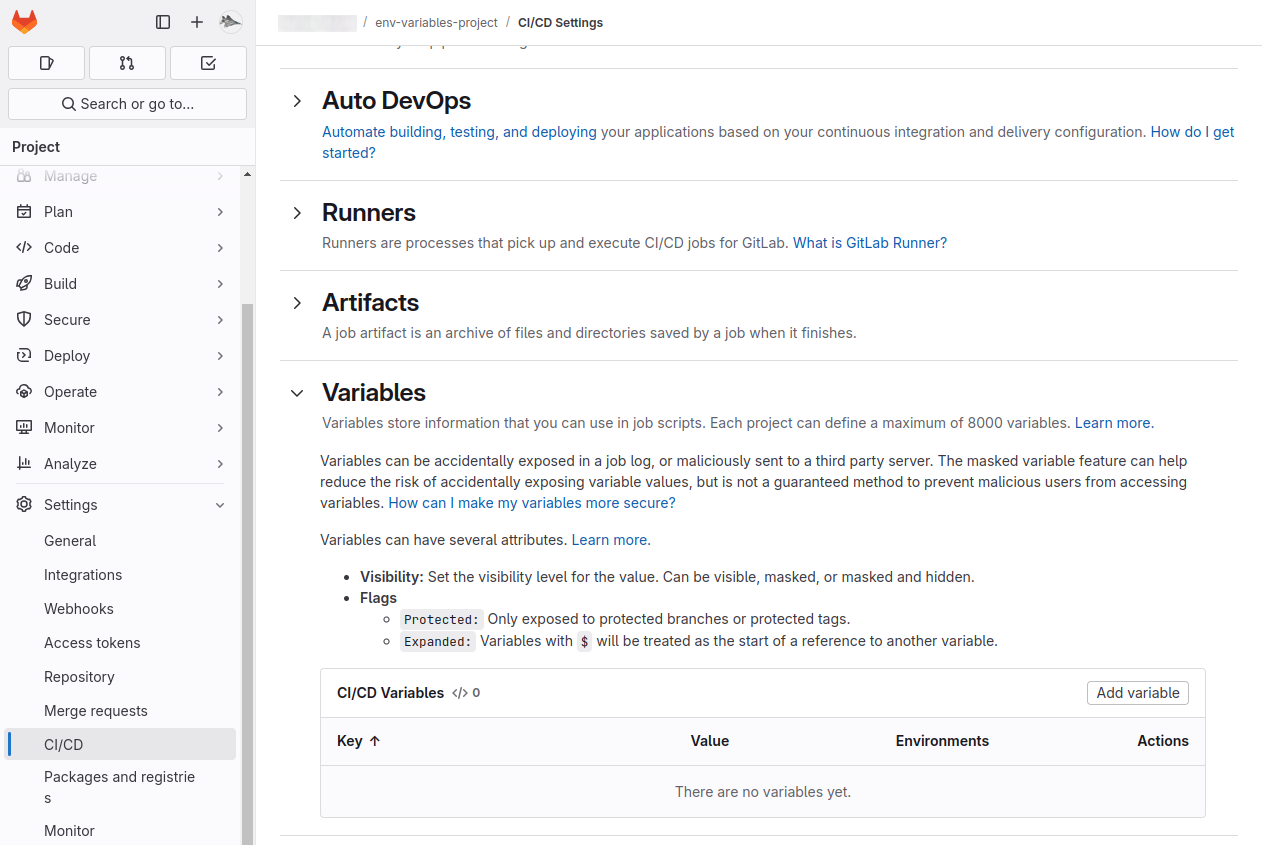
- Click Add Variable and provide:
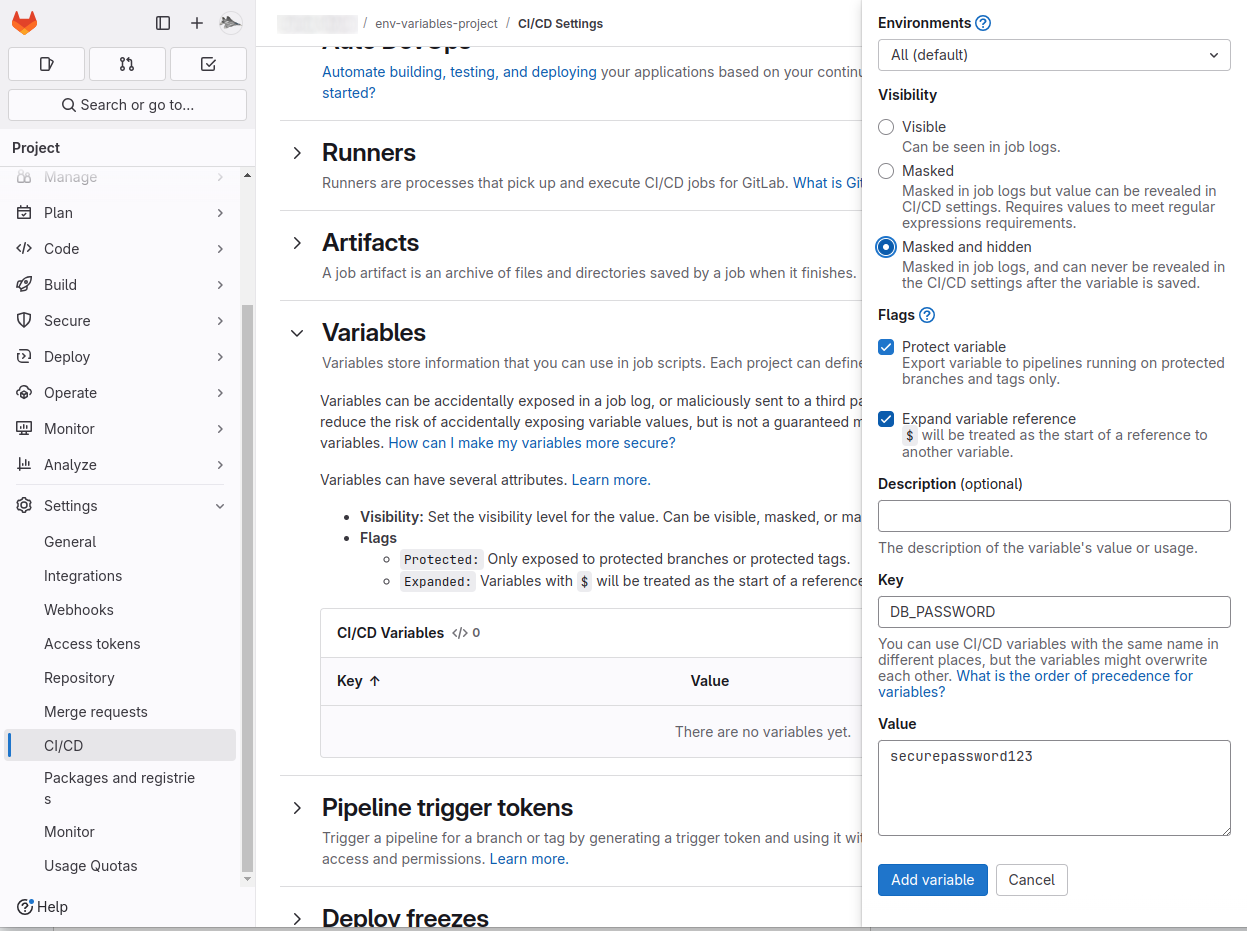
- Key: The variable name (e.g.,
DB_PASSWORD). - Value: The variable’s content (e.g.,
securepassword123). - Type:
Variable(default): Treated as an environment variable.File: The variable’s value will be written to a temporary file and the file path provided.
- Environment scope: Specify environments where the variable applies (e.g.,
production). - Protect variable: Restrict usage to pipelines running on protected branches or tags.
- Visibility: Choose from:
Visible(default): Value is accessible in jobs.Masked: Prevents the value from being printed in logs.Masked and hidden: Prevents both logs and UI visibility.
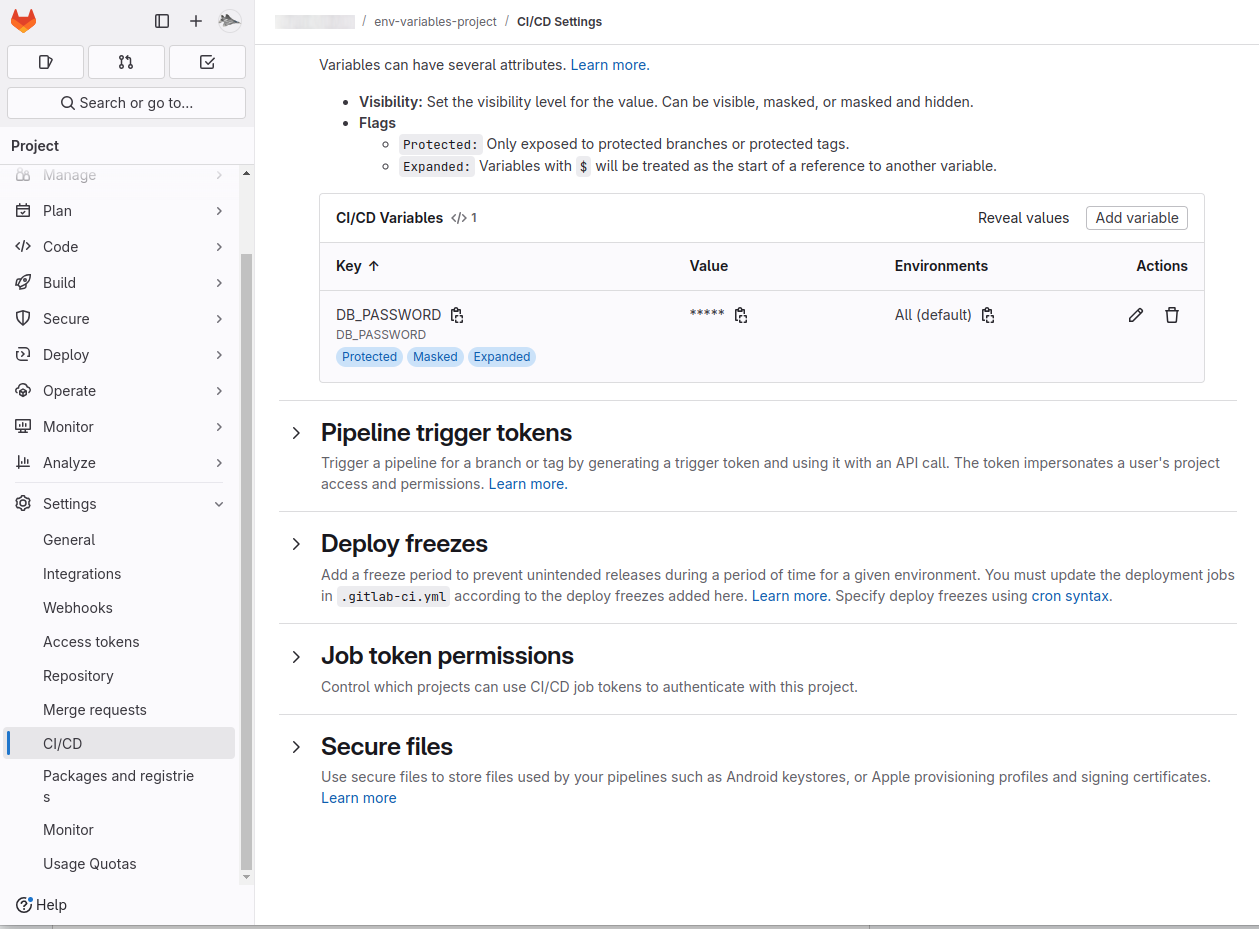
Code example:After defining a variable DB_PASSWORD in the UI, developers can use it in the .gitlab-ci.yml file:
deploy-job:
stage: deploy
script:
- echo "Deploying with password $DB_PASSWORD"Some important details about the code:
- Secure data storage: Storing variables in the UI avoids exposing sensitive data in the codebase.
- Scoping and protection: Define variables for specific environments or restrict their use to ensure security.
- Integration with pipelines: Variables stored in the UI are automatically accessible in job scripts.
CI/CD Variable Security
Security is crucial when managing CI/CD variables, especially for sensitive data like API keys, credentials, or tokens. GitLab provides several features to improve security:
Here are important recommendations for secure use:
Mask variables
Masked variables replace their values with [MASKED] in job logs to prevent accidental exposure.
Example:
deploy-job:
script:
- echo "Deploying with $DB_PASSWORD"Output in logs:
Deploying with [MASKED]Protect variables
Protected variables are only accessible in pipelines running on protected branches or tags.
Example:
- Define
DEPLOY_KEYas protected. - Pipelines triggered from non-protected branches cannot access
DEPLOY_KEY.
Use CI/CD Variables in Job Scripts
GitLab automatically exposes CI/CD variables as environment variables in job scripts. The syntax to access them depends on the shell or operating system.
Bash and sh:
test-job:
script:
- echo "Job ID is $CI_JOB_ID"PowerShell:
test-job:
script:
- Write-Output "Job ID is $env:CI_JOB_ID"Windows Batch:
test-job:
script:
- echo %CI_JOB_ID%Advanced usage:
You can assign values to variables dynamically during runtime. Use !VAR! in Windows Batch scripts for values with spaces or newlines.
Use CI/CD Variables in Other Variables
Variables can reference each other, enabling dynamic configurations in pipelines. This avoids redundancy and improves maintainability.
Code example:
variables:
BASE_URL: "https://api.example.com"
FULL_URL: "${BASE_URL}/v1"
api-call:
script:
- curl $FULL_URLImportant details about this code:
- Curly brackets ({}) are optional but help distinguish variable names from surrounding text.
- Variable expansion ensures that dependent variables update automatically if the base variable changes.
Managing and Securely Storing Environment Variables with Configu
Configu is a configuration management platform comprised of two main components, the stand-alone Orchestrator, which is open source, and the Cloud, which is a SaaS solution:
Configu Orchestrator
As applications become more dynamic and distributed in microservices architectures, configurations are getting more fragmented. They are saved as raw text that is spread across multiple stores, databases, files, git repositories, and third-party tools (a typical company will have five to ten different stores).
The Configu Orchestrator, which is open-source software, is a powerful standalone tool designed to address this challenge by providing configuration orchestration along with Configuration-as-Code (CaC) approach.
Configu Cloud
Configu Cloud is the most innovative store purpose-built for configurations, including environment variables, secrets, and feature flags. It is built based on the Configu configuration-as-code (CaC) approach and can model configurations and wrap them with unique layers, providing collaboration capabilities, visibility into configuration workflows, and security and compliance standardization.
Unlike legacy tools, which treat configurations as unstructured data or key-value pairs, Configu is leading the way with a Configuration-as-Code approach. By modeling configurations, they are treated as first-class citizens in the developers’ code. This makes our solution more robust and reliable and also enables Configu to provide more capabilities, such as visualization, a testing framework, and security abilities.


